Mix/Maxと組み合わせてgroup byしたときに、なぜかうまくグルーピングができない場合があってはまったことがあったのでメモ。
環境はMySQL 5.5.59
まずは、テーブルの生成
CREATE TABLE IF NOT EXISTS `test` ( `id` int(11) NOT NULL, `user_id` int(11) NOT NULL, `created` datetime NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1; INSERT INTO `test` (`id`, `user_id`, `created`) VALUES (1, 1, '2018-09-06 10:00:00'), (2, 1, '2018-09-06 12:00:00'), (3, 2, '2018-09-06 00:00:00'); ALTER TABLE `test` ADD PRIMARY KEY (`id`);
で、ここでuser_id毎にcreatedが最も古いデータでグルーピングして持ってきたいとすると、SQLは以下のような感じになります。
select `test`.`id` as `id` ,`test`.`user_id` as `user_id`,`test`.`created` as `created` from test where `test`.`created` in (select min(`test`.`created`) from `test` group by `test`.`user_id`) order by `test`.`user_id`;
これは、問題なくとれる。
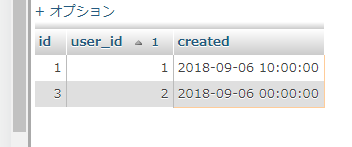
問題はここから。
データをいったん消して、id=1とid=2のcreatedの日時を一致させちゃうとどうなるか・・・
INSERT INTO `test` (`id`, `user_id`, `created`) VALUES (1, 1, '2018-09-06 10:00:00'), (2, 1, '2018-09-06 10:00:00'), (3, 2, '2018-09-06 00:00:00'); ALTER TABLE `test`
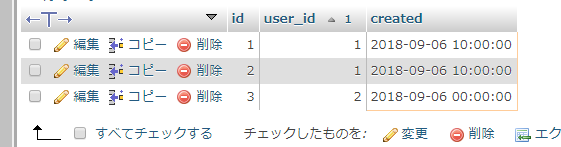
ふぁ!!!user_idが重複してるやんけ!!!
minやmaxは、値が一致しちゃうと、両方出しちゃうみたいです。どちらかだけでいいんだけどなぁ…。
普通に動作させている分にはあり得ないんですが、Unitテストでデータの追加テストとかしていて気が付きました。
うまい回避策が見つからなかったのですが、古いデータが分かればいいので、createdで抽出しているところをidに変更して対応しました。



